ESLint 동작 방식 이해
들어가며
Prettier, ESLint 등의 기술은 공기같습니다. 특히 CRA로 생성된 프로젝트 안에 ESLint가 미리 탑재되어 있어서 해당 기술이 언제, 어떻게 동작하는지 다들 별로 관심이 없습니다. 그리고 딱히 몰라도 일 하는 데는 큰 지장이 없습니다. 플러그인만 잘 조합해 사용한다면 좋은 코드 퀄리티를 유지할 수 있습니다. 그럼에도 불구하고 우리의 devDependencies 중 가장 큰 비율을 차지하는 해당 라이브러리가 어떻게 동작하는지 궁금해서 찾아봤고, 이를 간단하게 공유하고자 합니다.
이번 발표에서는 ESLint의 동작 방식에 대해 설명합니다. 아쉽게도 ESLint의 상세 설정 가이드 혹은 플러그인에 대해서는 다루지 않습니다. 추후 시간이 된다면 이 부분까지 함께 다루어 볼 예정입니다.
ESLint
ESLint는 ES와 Lint의 합성어입니다. ES는 EcmaScript, 즉 자바스크립트를 의미하며, Lint는 오래된 스웨터의 보푸라기 같은 것을 지칭하는 소프트웨어 용어입니다.
코드에서도 보푸라기가 존재합니다…
들여쓰기를 맞추지 않은 경우나 선언한 변수를 사용하지 않은 경우 등 코드의 가독성을 떨어뜨리는 문제점을 지칭합니다. 이러한 문제점을 해결하기 위해 코드의 오류나 버그, 스타일 등을 점검하는 것을 린트(Lint) 혹은 린터(Linter)라고 부릅니다.
자바스크립트와 같이 컴파일 과정이 없는 인터프리터 언어의 경우, 런타임 에러가 발생할 확률이 높기 때문에, 이 린트 작업을 통해 사전에 에러를 최대한 잡아주는 것이 중요합니다.
ESLint 동작 방식 이해
어떤 과정으로 ESLint 가 동작하는지 간략하게 표현한 그림입니다.
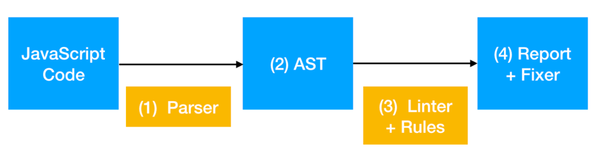
출처: https://tech.kakao.com/2019/12/05/make-better-use-of-eslint/
ESLint의 동작은 크게 두 가지로 나눌 수 있습니다.
첫째는 코드의 파싱과 AST(Abstract Syntax Tree)를 생성하는 것이고, 둘째는 생성된 AST를 기반으로 코드를 검사하여 규칙 위반을 찾아내는 것입니다.
1. Parser
ESLint 구문 분석기는 코드를 ESLint가 평가할 수 있는 추상 구문 트리로 변환합니다. 기본적으로 ESLint는 표준 자바스크립트 런타임 및 버전과 호환되는 내장 Espree 파서를 사용합니다.
사용자 정의 구문 분석기를 사용하면 ESLint가 비표준 JavaScript 구문을 구문 분석할 수 있습니다. 사용자 정의 구문 분석기는 공유 가능한 구성이나 플러그인의 일부로 포함되는 경우가 많으므로 직접 사용할 필요가 없습니다.
예를 들어, **@typescript-eslint/parser**는 TypeScript 코드를 파싱할 수 있도록 ESLint에 포함된 사용자 정의 파서입니다. 이 파서는 typescript-eslint 프로젝트에 포함되어 있으며, 일반적으로 이 프로젝트의 규칙을 사용하거나 TypeScript를 사용하는 프로젝트에서 ESLint를 실행할 때 자동으로 사용됩니다.
토큰화(Tokenization)
자바스크립트 코드는 토큰화(Tokenization) 및 구문 분석(Parsing) 두 가지 단계를 거칩니다.
토큰화 과정에서 코드는 어휘 분석 과정에 의해 문자열로 읽히면서 토큰 목록으로 쪼개집니다.

출처: https://itchallenger.tistory.com/709
구문 분석(Pasring)
토큰화 작업의 결과로 토큰 배열로 변경된 코드들은 AST 파서(기본적으로 espree)를 통해 전달됩니다.
이 파서는 AST 노드 사이에 종속성을 성정하여 AST 노트 트리로 변환합니다.
출처: https://itchallenger.tistory.com/709
기본적으로 ESLint는 Espree 파서를 사용하며, 이는 표준 자바스크립트 런타임 및 버전과 호환됩니다.
{
"parser": "@typescript-eslint/parser"
}기본 파서인 Espree외에 사용자 지정 파서를 사용 할 수 있는데, 예를 들어 보통 js 워크스페이스에서는 @babel/eslint-parser를 사용하고 ts 워크스페이스인 경우 @typescript-eslint/parser를 사용합니다.
eslint parser에 대해 더 자세하게 알고 싶다면
2. AST(Abstract Syntax Tree)
컴퓨터 과학에서 추상 구문 트리(abstract syntax tree, AST), 또는 간단히 구문 트리(syntax tree)는 프로그래밍 언어로 작성된 소스 코드의 추상 구문 구조의 트리이다. 이 트리의 각 노드는 소스 코드에서 발생되는 구조를 나타낸다. 구문이 추상적이라는 의미는 실제 구문에서 나타나는 모든 세세한 정보를 나타내지는 않는다는 것을 의미한다. 예를 들어, 그룹핑을 위한 괄호는 암시적으로 트리 구조를 가지며, 분리된 노드로 표현되지는 않는다. 마찬가지로, if-condition-then 표현식과 같은 구문 구조는 3개의 가지에 1개의 노드가 달린 구조로 표기된다.
https://ko.wikipedia.org/wiki/추상구문트리

말로는 이해가 잘 안되니 Javascript 구조에 따른 AST의 구조를 JSON 포맷으로 확인해보겠습니다.
- 그래서 AST가 뭐라고?
 AST(Abstract Syntax Tree)는 컴파일러에서 널리 사용되는 자료구조로 소스코드의 구조를
트리 형태로 표현한 것입니다. AST를 구성하고 있는 노드는 자신이 어떤 노드인지를
알려주는 노드 타입, 소스 코드에서 노드의 위치, 하위 자식 노드들에 대한 레퍼런스
등을 가지고 있습니다. AST에 대해 더 자세하게 알고 싶다면 해당 문서를
참고하시면 좋습니다.
AST(Abstract Syntax Tree)는 컴파일러에서 널리 사용되는 자료구조로 소스코드의 구조를
트리 형태로 표현한 것입니다. AST를 구성하고 있는 노드는 자신이 어떤 노드인지를
알려주는 노드 타입, 소스 코드에서 노드의 위치, 하위 자식 노드들에 대한 레퍼런스
등을 가지고 있습니다. AST에 대해 더 자세하게 알고 싶다면 해당 문서를
참고하시면 좋습니다.
ESLint 뿐만 아니라 실제 프로덕션 코드로 올라가는 것은 아니지만, 개발 과정에서 중요한 역할을 하는 **devDependencies**에 의존성이 있는 자바스크립트 트랜스파일링, CSS pre-processor, prettier 기능들은 모두 AST를 기반으로 동작합니다.
실제 Espree가 만드는 AST 노드에는 더 많은 데이터가 담겨 있는데요. 각 노드 타입에 대한 스펙이 궁금하신 분은 ESTree spec 을 참고하시면 됩니다.
3. Linter + Rule
린터(Linter)는 설정에 따라 규칙(Rule)을 생성하고, 이를 위해 파서(Parser)가 생성한 추상 구문 트리(AST)를 탐색하며 노드 타입과 같은 이름의 이벤트를 발생시킵니다. 발생한 이벤트는 규칙(Rule)의 리스너에게 전달되어 해당 노드가 규칙을 지키고 있는지 검사합니다. 만약 규칙을 위반하는 경우, 이를 보고(Report)하며 가능한 경우 코드를 자동으로 수정하여 규칙을 지키도록 하는 Fixer를 생성할 수도 있습니다.
간단히 말하면, ESLint는 코드를 분석하여 AST를 만들고, 이를 기반으로 지적하고 싶은 코드를 룰로 저장하는 도구입니다.
동작 방식을 이해하기 위해 간단한 예제로 테스트해보겠습니다.
예제
한 글자 짜리 변수를 막고, 만약 이 규칙을 어긴다면 ‘바보’라고 변수명을 바꾸는 ESLint 룰을 만든다고 가정해보겠습니다.
Eslint Parse Demo 페이지에서 변수 선언문 트리를 만들면 아래와 같은 AST를 확인할 수 있습니다.
const h = "hello world";{
"type": "Program",
"start": 0,
"end": 23,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 23,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 23,
"id": {
"type": "Identifier",
"start": 6,
"end": 7,
"name": "h"
},
"init": {
"type": "Literal",
"start": 10,
"end": 23,
"value": "hello world",
"raw": "'hello world'"
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}해당 AST 구조를 통해 구현해야할 로직을 정리해보자면 아래와 같습니다
- AST노트 타입(type)이 변수 선언자(VariableDeclarator)일때
- 노드의 이름(node.id.name)이 1글자라면
- 린트 에러를 발생시키고, 새로운 변수명으로 수정한다.
아래는 규칙을 기반으로 만들어본 eslint의 Rule입니다.
const REPLACE_NAME = "바보";
module.exports = {
meta: {
// ...
// eslint가 자동으로 수정할 수 있도록 허용하는 옵션
fixable: true
},
create(context) {
return {
// 1. 노드 타입이 VariableDeclarator일떄
VariableDeclarator(node) {
const { name } = node.id;
// 2. 노드의 이름(node.id.name)이 1글자라면
if (name.length < 2) {
// 3. 린트 에러를 발생시키고, 새로운 변수명으로 수정한다.
context.report({
node,
data: { outOfRuleName: name },
message: `'{{outOfRuleName}}()' 는 한 글자 변수명이라 사용할 수 없습니다.`,
fix: (fixer) => fixer.replaceText(name, REPLACE_NAME)
});
}
}
};
}
};예제 코드를 보면 meta 객체에 fixable 속성이 true로 설정되어 있어, eslint가 자동으로 수정할 수 있는 규칙을 가지고 있습니다. fixable 속성이 true로 설정되면, 린트가 발견한 문제를 자동으로 수정할 수 있는 패치(patch)를 제공합니다.
그리고 create 메서드는 해당 규칙을 실행할 함수를 반환합니다. 이 함수는 AST를 순회하다가 일치하는 패턴을 찾을 때마다 실행됩니다.
위의 코드에서는 **VariableDeclarator**라는 AST 노드 타입에 대한 처리를 정의하고 있습니다. VariableDeclarator 노드는 변수 선언문을 나타냅니다. 규칙이 실행될 때 린트 엔진은 문서를 분석하며 해당 노드를 발견하면 규칙에 따라 처리를 수행합니다.
매개변수(node)로는 VariableDeclarator타입에 해당하는 노드가 들어옵니다.
이후 노드의 id 속성에서 변수 이름을 가져와 변수 이름의 길이를 확인합니다. 이름의 길이가 1글자 미만인 경우, context.report() 함수를 사용하여 어디에 어떤 문제가 있는지를 보고합니다.
4. Report + Fixer
예제를 통해 context.report() 함수가 어디에 어떤 문제가 있는지 보고하는 역할을 한다는 걸 알았습니다.
context.report({
node,
data: { outOfRuleName: name },
message: `'{{outOfRuleName}}()' 는 한 글자 변수명이라 사용할 수 없습니다.`,
fix: (fixer) => fixer.replaceText(name, REPLACE_NAME)
});context.report()함수는 메시지(message와 노드(node)정보를 전달하여 문제를 발견하면 보고하는 역할을 담당합니다. 메시지는 출력될 에러 텍스트 정보가 포함되어 있으며, 노드는 실제 소스코드에서 해당 코드의 위치가 어디지인지 알고 있디 때문에 규칙을 어긴 코드의 위치도 알 수 있습니다.
Fixer는 에러 발생 시 코드를 규칙에 맞게 수정하는 역할을 합니다. fixer객체는 수정 메서드를 제공하며, 이를 사용하여 특정 토큰이나 노드가 가지고 있는 값을 수정하거나 노드를 삭제하거나 삽입할 수 있습니다. 요건 ESLint 실행 시 –fix 옵션을 사용하면 동작하게 됩니다.
참고 자료